

我们都知道作为搜索引擎头把交椅的谷歌,每天都要处理数以亿计的数据,面对这么大量的数据,如何进行数据的计算成为了头疼的问题。不过谷歌的人才济济,很快就有人发明了MapReduce框架,通过它就解决了数据的分布式计算问题。
诞生历史
在2004年的时候,谷歌发布了一篇论文,论文里面详细讲述了谷歌在内部是如何进行海量数据的分布式计算的。
开源社区根据这篇论文实现了
自己的分布式计算架构,也就是我们常说的hadoop框架,有了它,很多大公司也可以像谷歌一样进行大数据的计算。
分而治之
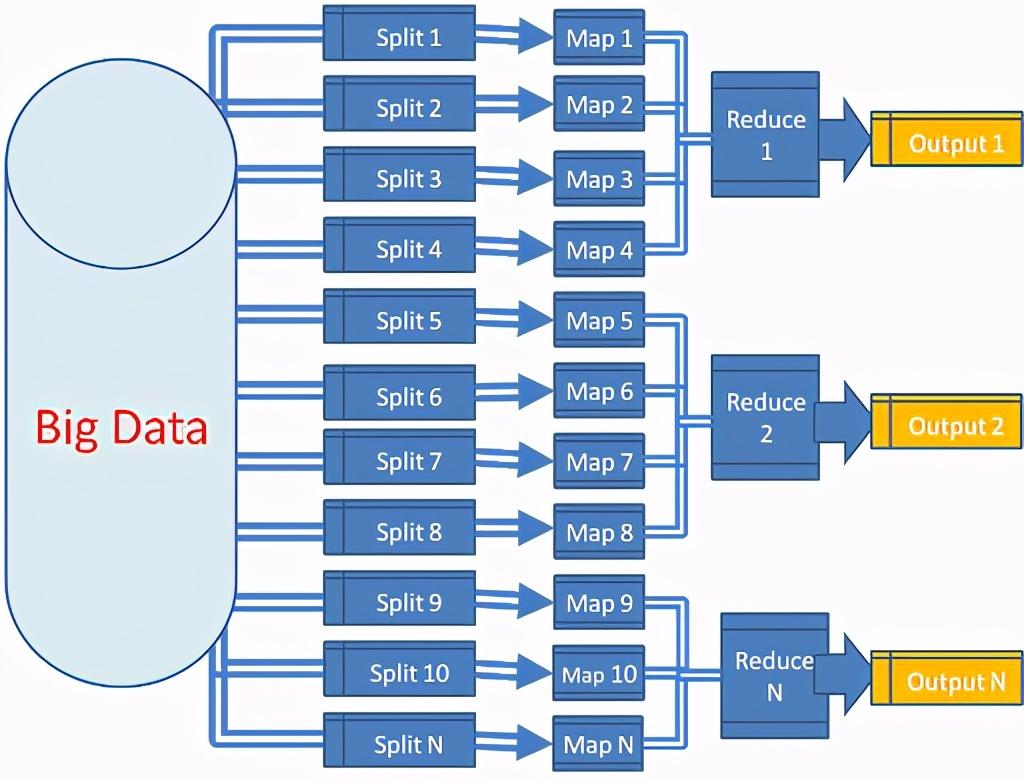
MapReduce的核心思想就是分而治之,也就是我们经常提到的将大问题划分成一个个小问题,然后一点点去解决小问题,当小问题解决了,大问题也就迎刃而解了。
分治法要求我们先拆分问题,然后得到每个单独结果之后再进行合并,最后得到的就是最后索要计算问题的答案。
计算过程
MapReduce进行计算的过程主要分为6个步骤。
inputsplitmapshufflereducefinalize
通过上面的步骤,就可以实现数据分而治之,就可以将数据进行分布式计算,就可以将数据拆分成一个个小问题,然后得到最终的计算结果
案例分析
我们可以假设我们有一个文档,文档的每行都有很多单词,我们要统计这个文档中每个单词出现的行号,其实这个问题就是我们经常听到的倒排索引。
文档如下(逗号前面的是行号,后面的是句子):
1,tom is good
2,you are good
3,tom and you are good
首先我们将文档作为input输入对象,然后我们进行split拆分,让不同的进程或者不同的任务去处理不同的行,比如我们有task1,task2,task3三个任务。
task1
1,tom is good
task2
2,you are good
task1
3,tom and you are good
进行任务拆分之后,我们需要使用map进行数据的统计(逗号前面是单词,后面是出现的行号)
task1
tom,1
is,1
good,1
task2
tom,1
is,1
good,1
task3
you,2
are,2
good,2
数据统计之后,我们需要使用shuffle进行数据的排序整理
and,3
are,2
are,3
good,1
good,2
good,3
is,1
tom,1
tom,3
you,2
you,3
再然后,我们就需要进行reduce规约操作,进行数据的合并
and:3
are:2,3
good:1,2,3
is:1
tom:1,3
you:2,3
最后,我们将结果进行输出就可以了。
总结
通过上面的例子我们可以理解到MapReduce的核心思想,通过将大数据拆解成独立的小块数据,每个小块数据可以并行计算,大大提高了计算的效率,同时也降低了计算的开销,通过Map进行数据的拆分,通过reduce进行数据的合并,最后得到我们想要的计算结果。
正所谓天下大势,分久必合合久必分。

 QQ客服专员
QQ客服专员 电话客服专员
电话客服专员